This is the first technical chapter of the journey of building skott, an open-source Node.js library. Today’s topic: building a static analysis tool.
What is static analysis?
Static analysis is the process of analyzing source code without running the application. You probably already use many tools that leverage it behind the scenes:
Linters are tools that fully leverage static analysis to flag programming errors, bugs, stylistic issues and suspicious constructs without ever executing the code.
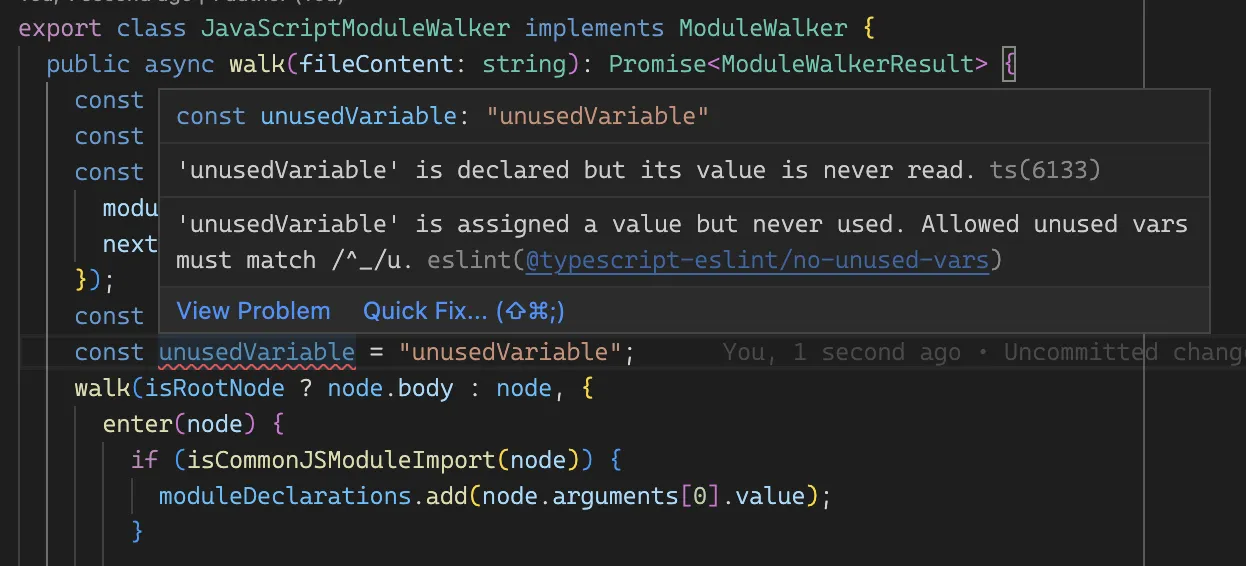
As you can see above, ESLint detects an unused variable and flags it as an error (according to the provided configuration).
How does static analysis work behind the scenes?
The answer comes in three steps:
- What is a parser
- What is an Abstract Syntax Tree
- How to use an Abstract Syntax Tree
Building static analysis tools is not a trivial task, so we’ll only scratch the surface here, but you’ll have enough to go further if you want to.
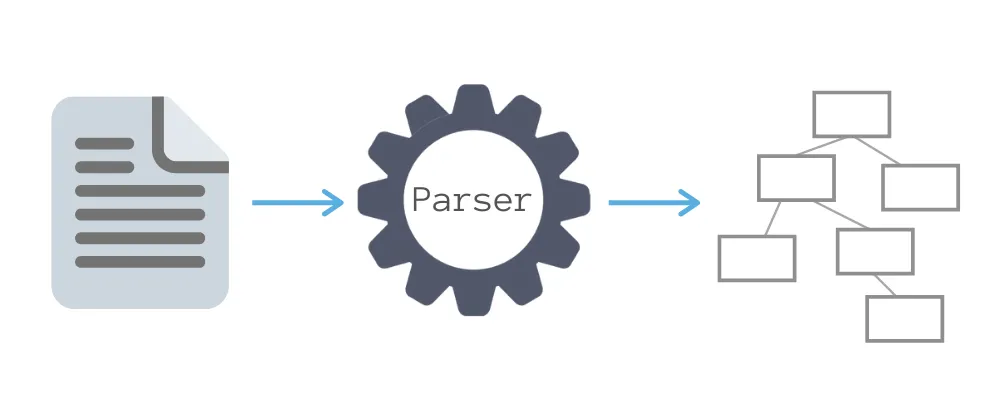
1. What is a parser
A parser is a program that generates an intermediary data structure from an input string. Parsing is most typically done in two phases:
-
Lexical analysis (also known as lexing or tokenization)
The goal of tokenization is to generate tokens from the input program, which is only a raw string at this point (any source file, really:
.js,.rs,.go,.py, etc.). Tokens are collections of characters that describe pieces of code. -
Syntactic analysis
Following tokenization, syntactic analysis takes the produced tokens and generates an intermediary data structure describing those tokens and their relationships. Spoiler: this structure is most often an Abstract Syntax Tree (AST).
Here is a schema of a common parsing process:

2. What is an Abstract Syntax Tree
As mentioned, an Abstract Syntax Tree is one of the data structures that can be generated while parsing source code (others exist, such as Concrete Syntax Trees, depending on the use case).
The goal of this intermediate representation is to have a standardized way of representing the code that is easy to work with, without any loss of information.
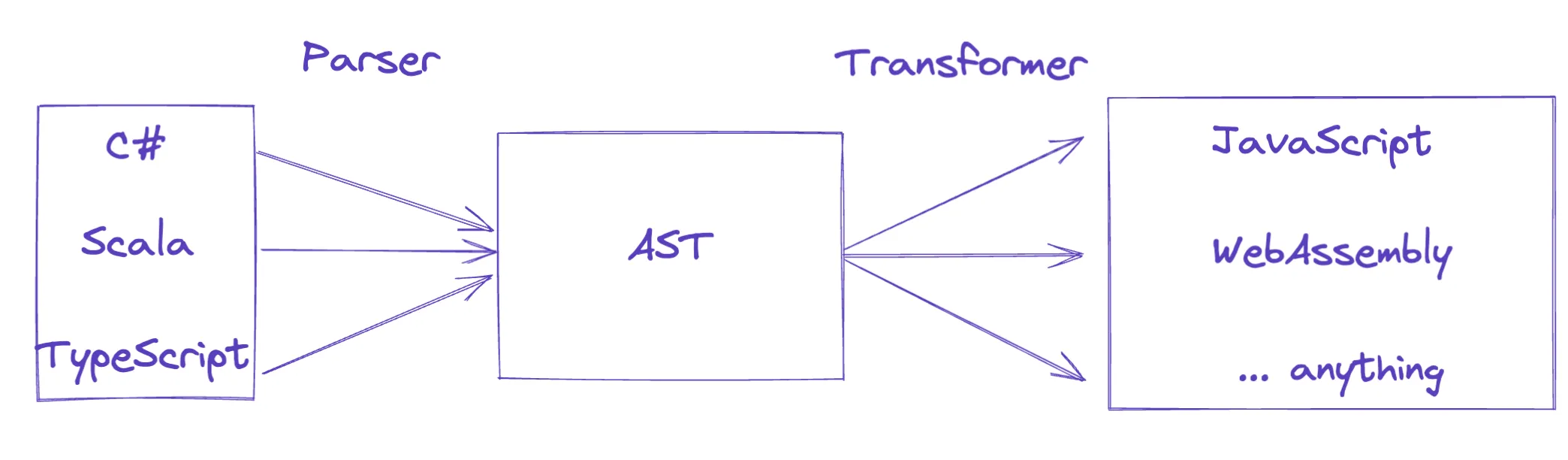
The keyword is standardized. Because the AST is an intermediary structure, the overall goal is to be able to transform the tree into anything we want, for example to produce a program in an entirely new language, such as generating JavaScript from Scala, or, more commonly, JavaScript from TypeScript.
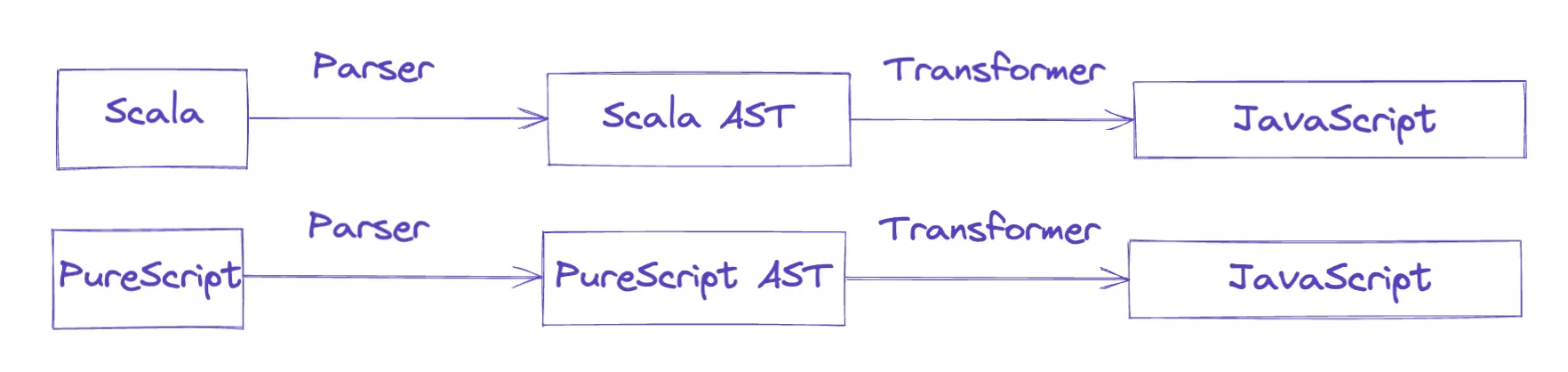
To enable that, each ecosystem/language has strict specifications describing the standard shape of its own AST. For JavaScript, this is the ESTree spec. This standardized format lets any parser (written in any language) produce a common AST that can then be interpreted by any interpreter (also written in any language).
3. How to use an Abstract Syntax Tree
For compilers, an AST is an intermediary data structure that can be transformed to produce byte code or another source target: e.g. TypeScript emits JavaScript using its own AST.
In the context of static analysis, however, the AST is most often our final data structure, because it lets us inspect source-code patterns directly (no further transformation needed).
By relying on the spec that describes the AST’s shape, we, as static analysis developers, can determine any static rule or condition. It’s just a matter of finding the right data-structure combinations.
To explore AST structures for various languages, I highly recommend AST Explorer.
Let’s wrap it up by example
To demonstrate a small static analysis tool in action, here is one use case from skott, a library that builds a directed graph of relationships between the files of a Node.js project.
If you’re not fully sure of the purpose of directed graphs, see the series I wrote on the topic.
To build that directed graph, skott has to:
- take the entrypoint of the project and parse it,
- statically find the import/export statements from the AST,
- recursively follow the imported/exported files until all files have been discovered.
Let’s do this.
1. Parse the entrypoint
index.js
import { runMain } from "./program.js";
import { makeDependencies } from "./dependencies.js";
// do something with runMain and makeDependenciesOnce we read the entrypoint, we can use skott to extract the import statements. Here is a simplified snippet from skott’s codebase:
async function walk(fileContent: string): Promise<ModuleWalkerResult> {
const moduleDeclarations = new Set<string>();
const { parseScript } = await import("meriyah");
const node = parseScript(fileContent, {
module: true,
next: true
});
const isRootNode = node.type === "Program";
walkAST(isRootNode ? node.body : node, {
enter(node) {
if (isEcmaScriptModuleDeclaration(node)) {
moduleDeclarations.add(node.source.value);
}
}
});
return { moduleDeclarations };
}We import parseScript from meriyah, a JavaScript parser (it could have been babel, acorn or swc: it doesn’t matter, as long as they correctly implement the spec). Parsing the file content returns the root node of the Abstract Syntax Tree. From there, the only thing left to do is traverse the whole tree recursively and find the import statements.
To keep the example simple, we only track ECMAScript modules here, but skott also deals with CommonJS modules.
How do we find an import statement inside the AST?
Let’s look at the ESTree spec for es2015 to see how an import statement is represented:
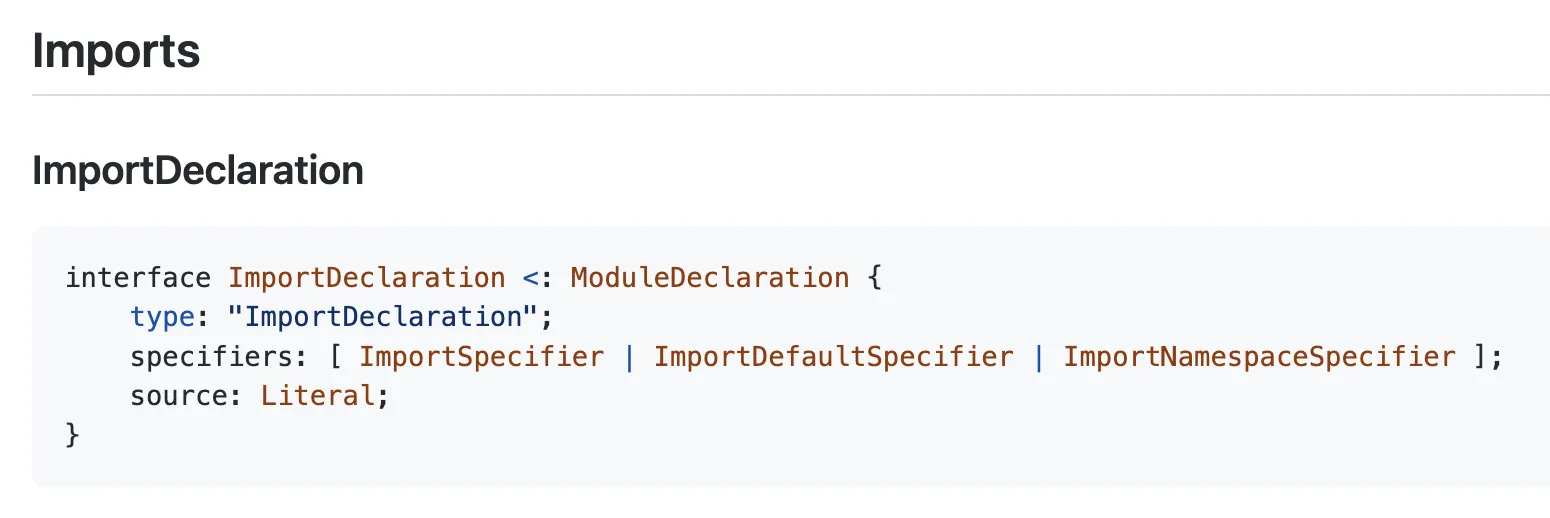
Pretty simple: any time we meet a node whose type === "ImportDeclaration", we know it’s an import statement. So here’s the function to detect an es2015 import statement:
function isEcmaScriptModuleImport(estreeNode: TreeNode): boolean {
return estreeNode.type === "ImportDeclaration";
}Great: we’re now able to find all import statements from any JavaScript file. Using the AST, we could also retrieve where the import is located in the file and, say, highlight it in VS Code.
Thanks to our static analysis, we can now generate and display the graph from all the collected imports:
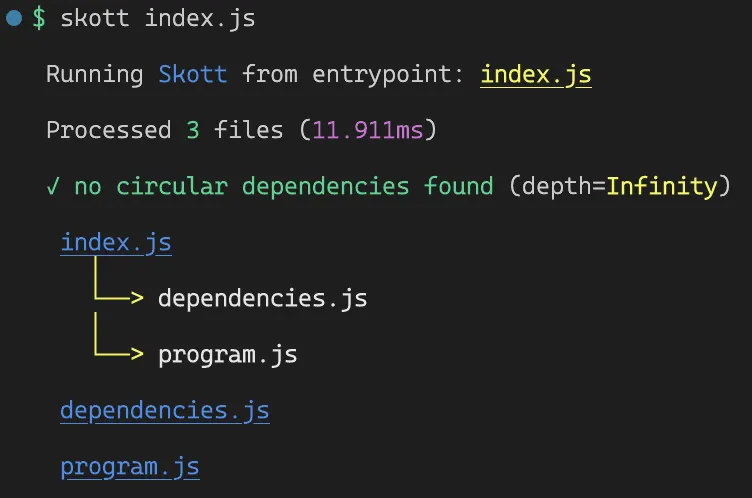
Three nodes have been found (the only three files of the sample project), and dependencies have been established between index.js and its two imported children.
Conclusion
If you made it this far, you’ve probably grasped the foundations of parsers and Abstract Syntax Trees, and that’s exactly the point.
The next chapter of the series covers Test-Driven Development and Dependency Injection, the disciplines that made skott’s whole exploring/parsing/analysis pipeline fully testable.
skott is open source: stars, issues and feedback are welcome on GitHub.