La plupart des applications web vont chercher leurs données sur le réseau à chaque interaction. C’est souvent justifié : les données sont dynamiques, réagissent aux actions de l’utilisateur ou se rafraîchissent à intervalle régulier. Mais ce n’est pas toujours le cas, et c’est là que le bât blesse : combien de fois récupère-t-on, à grands frais de latence, une donnée qui n’a pas bougé depuis la dernière requête ? Le caching est la réponse historique à ce gaspillage, et il commence par quelque chose que vous avez déjà sous la main : le protocole HTTP.
Ce premier volet d’une série consacrée au caching pose les fondations. Avant de plonger dans les mécanismes plus avancés (d’où vient réellement le gain de performance puis l’invalidation et l’éviction des données mises en cache), il faut comprendre comment, avec une seule ligne d’en-tête HTTP, on peut déjà transformer les performances d’une application.
Le problème : l’over-fetching
Pour beaucoup d’applications, chaque affichage déclenche un nouvel aller-retour réseau. Tant que la donnée évolue à chaque instant, cette fraîcheur a un sens. Mais prenez un dashboard de visualisation dont les chiffres ne sont actualisés qu’une fois par jour, lorsque le data lake est rafraîchi : recharger ces mêmes données à chaque visite, à chaque rafraîchissement automatique, à chaque utilisateur, n’apporte strictement rien. C’est de l’over-fetching : on récupère plus, et plus souvent, que nécessaire.
Les conséquences ne sont pas anecdotiques. L’over-fetching dégrade mécaniquement les performances perçues (chaque requête coûte sa latence réseau), surcharge l’infrastructure dans son ensemble, du serveur applicatif jusqu’à la base de données, et finit par peser sur l’expérience utilisateur. Sans compter l’aspect le moins visible mais bien réel : tout ce trafic inutile consomme de l’énergie. Servir cent fois la même réponse immuable n’a rien d’éco-responsable.
Le caching, une solution universelle
Le caching est une technique de persistance qui permet d’accéder très rapidement au résultat d’une opération déjà effectuée, ou à une ressource déjà récupérée lors d’une action précédente. Au lieu de refaire le travail (interroger le serveur, frapper la base de données, retransférer la charge utile sur le réseau), on réutilise une copie conservée à portée de main.
L’idée est universelle parce qu’elle s’applique à presque toutes les couches d’un système. Mais la manière la plus simple d’en bénéficier, et celle qui ne demande aucune infrastructure supplémentaire, passe directement par HTTP grâce au header Cache-Control. Cet en-tête, posé par le serveur sur ses réponses, définit la stratégie de mise en cache : qui a le droit de conserver la ressource, et pendant combien de temps.
Mettre en cache avec HTTP : le header Cache-Control
Cache-Control distingue deux grandes familles de caches, selon que la copie conservée est réservée à un seul utilisateur ou partagée entre plusieurs. Le choix entre les deux n’est pas un détail technique : il détermine ce que vous avez le droit d’y stocker et où la charge se reporte.
Le cache privé (Cache-Control: private)
Un cache privé est propre à chaque utilisateur. Il est nativement géré par le navigateur, qui intercepte de manière transparente toutes les requêtes et réponses concernées : on peut y conserver des réponses d’API, mais aussi des images, des scripts ou des documents.
Cache-Control: private, max-age=3600Son principal avantage tient à cette isolation : chaque utilisateur dispose de sa propre version du cache, sur son propre navigateur. Les données peuvent donc être personnalisées, authentifiées, et rester potentiellement disponibles hors-ligne.
Sa limite est le revers de la même médaille. La charge d’infrastructure reste entière dès lors que de nombreux utilisateurs uniques émettent leur première requête : chacun doit constituer son cache de zéro, et c’est toujours le serveur d’origine qui répond. Un cache privé ne mutualise rien entre les utilisateurs.
Un point de vigilance enfin : n’y stockez jamais de données réellement sensibles. Les caches des navigateurs sont une cible d’attaques, et une donnée confidentielle laissée sur le disque d’un poste partagé peut fuiter.
Le cache partagé (Cache-Control: public)
Un cache partagé, lui, est réutilisable par de nombreux utilisateurs à la fois. Au-delà du navigateur, il peut être géré par un CDN (Content Delivery Network) ou par d’autres serveurs intermédiaires comme un reverse proxy, NGINX ou HAProxy, par exemple.
Cache-Control: public, max-age=3600L’intérêt est considérable : la première requête d’un utilisateur réchauffe le cache pour tous les suivants. Les performances s’améliorent de façon distribuée, quelle que soit la charge utilisateur, et le serveur d’origine est déchargé d’autant.
L’inconvénient découle de sa nature publique : les données stockées ne doivent pas être sensibles, et il devient difficile de conserver une version spécifique à chaque utilisateur. Attention en particulier avec la directive public : n’importe quelle réponse, y compris une réponse authentifiée portant un header Authorization, peut se retrouver distribuée telle quelle à plusieurs utilisateurs. Une donnée privée servie depuis un cache partagé, c’est une fuite garantie.
Contrôler la durée de vie : max-age et s-maxage
Définir qui peut mettre en cache ne suffit pas ; il faut aussi préciser combien de temps la copie reste valide. Deux directives s’en chargent, et leur différence est subtile mais décisive :
max-ages’applique à tous les caches, y compris celui du navigateur. Sa valeur est exprimée en secondes (max-age=3600= une heure).s-maxagene s’applique qu’aux caches partagés : CDN et proxies. Le « s » signifie shared. Elle est ignorée par le navigateur, et prend le pas surmax-agepour les caches partagés.
En combinant le type de cache (private / public) et la directive de durée (max-age / s-maxage), on obtient trois stratégies de référence, illustrées ci-dessous.
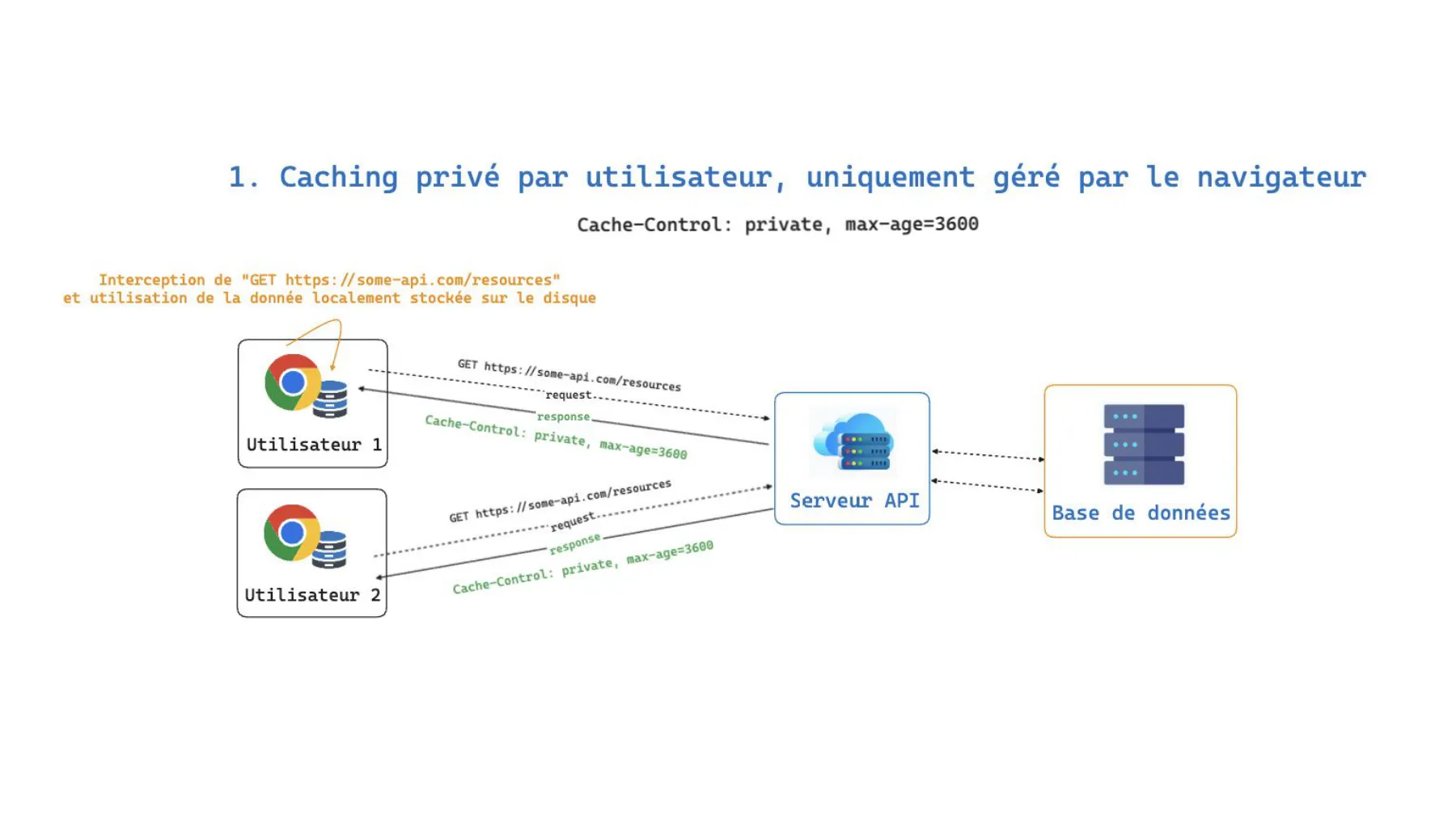
1. Cache privé, géré uniquement par le navigateur
Cache-Control: private, max-age=3600Chaque navigateur intercepte la requête GET https://some-api.com/resources et réutilise la donnée stockée localement sur le disque pendant une heure. Le serveur API n’est sollicité qu’à la première requête de chaque utilisateur. Rien n’est mutualisé entre eux.
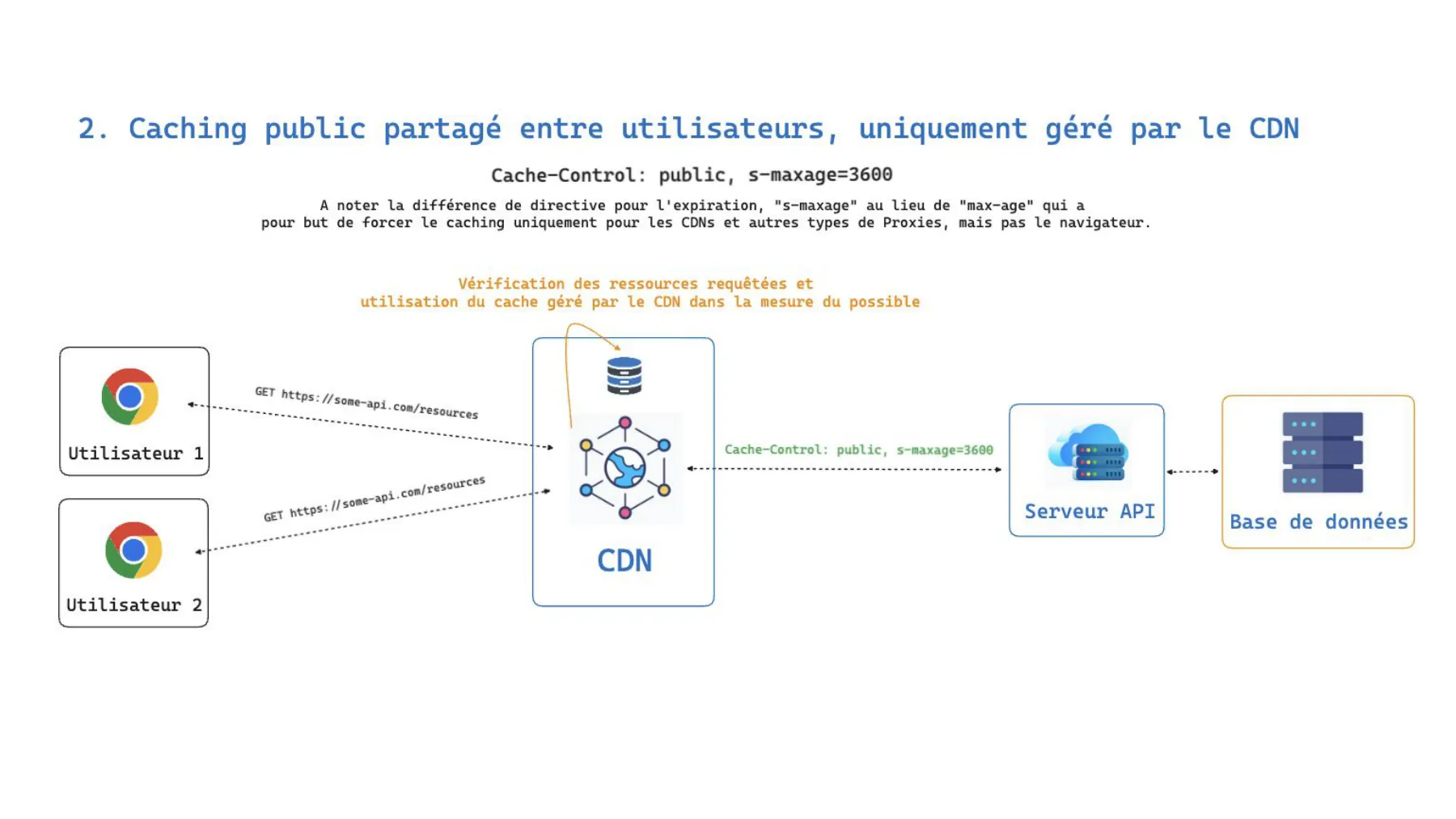
2. Cache public, géré uniquement par le CDN
Cache-Control: public, s-maxage=3600Ici, le choix de s-maxage plutôt que max-age est délibéré : il force la mise en cache uniquement au niveau des CDN et autres proxies, sans impliquer le navigateur. Le CDN vérifie les ressources demandées et sert sa copie partagée tant qu’elle est valide, n’interrogeant le serveur API que lorsque c’est nécessaire. La première requête d’un utilisateur bénéficie à tous les autres.
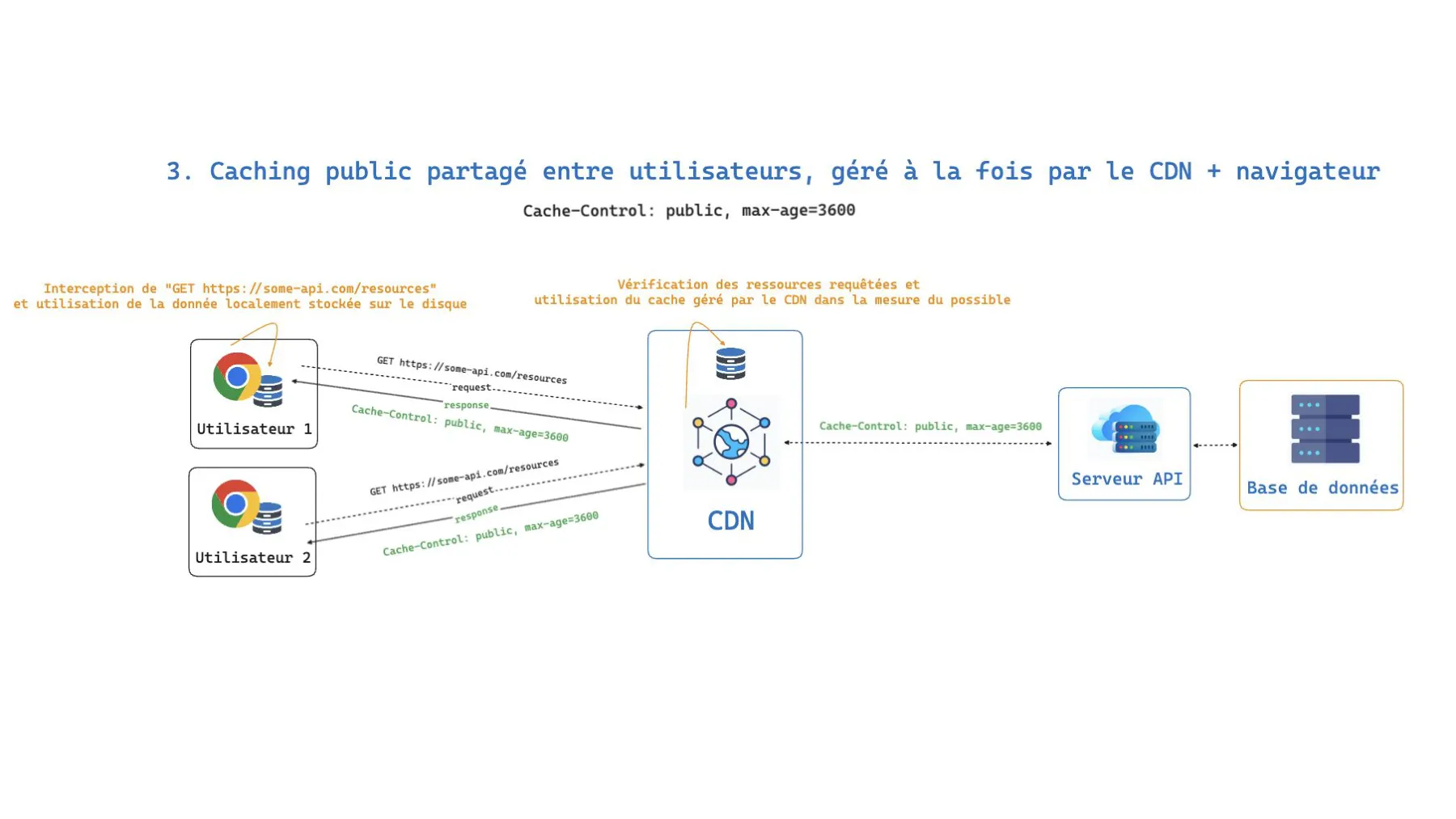
3. Cache public, géré à la fois par le CDN et le navigateur
Cache-Control: public, max-age=3600Avec public, max-age, la mise en cache opère sur les deux niveaux simultanément : le navigateur conserve sa copie locale et le CDN maintient une copie partagée. C’est la stratégie la plus agressive en termes de performance (la requête peut être résolue sans même quitter le poste de l’utilisateur) mais aussi celle qui demande le plus de prudence quant aux données exposées.
Conclusion
Avec une seule ligne d’en-tête HTTP, on transforme déjà la donne : en choisissant le bon type de cache (private ou public) et la bonne directive de durée (max-age ou s-maxage), on supprime l’over-fetching, on décharge l’infrastructure et on accélère l’application sans écrire une ligne de logique applicative. Le caching HTTP est le point d’entrée le plus économique vers la performance.
Mais poser un Cache-Control n’est qu’un début. Encore faut-il comprendre pourquoi ce gain existe et où il se matérialise réellement dans la chaîne de traitement : c’est l’objet du deuxième volet de cette série. Et surtout, une donnée mise en cache finit toujours par devenir obsolète : savoir invalider et expulser au bon moment, sans servir de la donnée périmée, est le sujet le plus délicat du caching, que nous aborderons dans le troisième et dernier épisode.