Voici le premier chapitre technique de l’aventure de la construction de skott, une bibliothèque Node.js open source. Le sujet du jour : construire un outil d’analyse statique.
Qu’est-ce que l’analyse statique ?
L’analyse statique est le processus qui consiste à analyser du code source sans exécuter l’application. Vous utilisez probablement déjà de nombreux outils qui s’appuient dessus en coulisses :
Les linters sont des outils qui exploitent pleinement l’analyse statique pour signaler des erreurs de programmation, des bugs, des problèmes de style et des constructions suspectes, sans jamais exécuter le code.
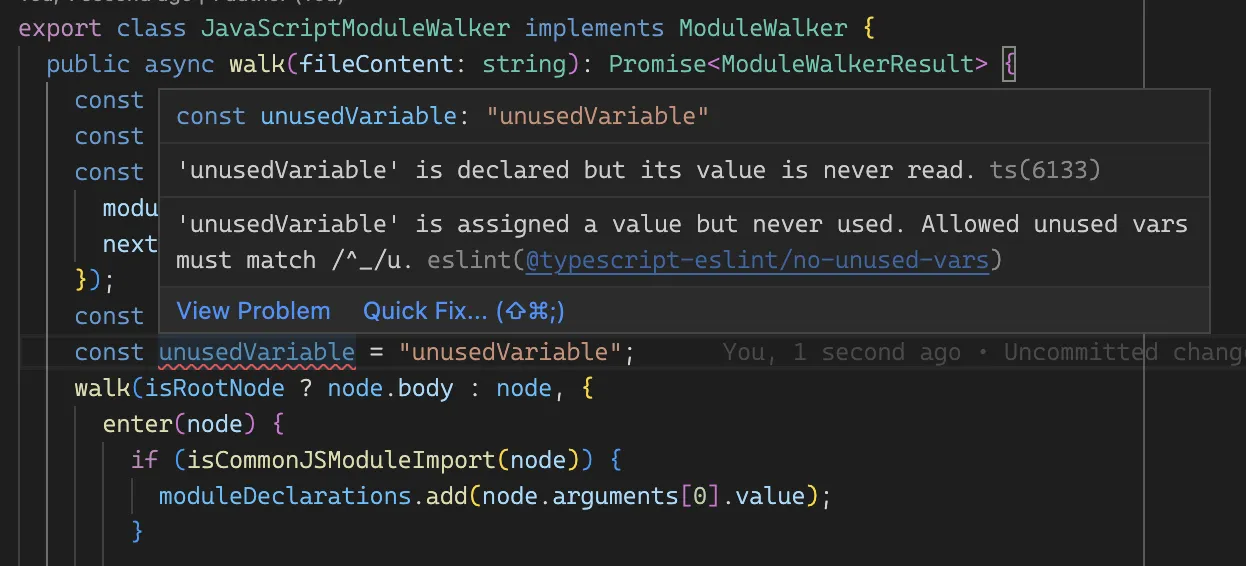
Comme vous pouvez le voir ci-dessus, ESLint détecte une variable inutilisée et la signale comme une erreur (selon la configuration fournie).
Comment fonctionne l’analyse statique en coulisses ?
La réponse tient en trois étapes :
- Qu’est-ce qu’un parser
- Qu’est-ce qu’un arbre syntaxique abstrait
- Comment utiliser un arbre syntaxique abstrait
Construire des outils d’analyse statique n’est pas une tâche triviale, nous ne ferons donc qu’effleurer le sujet ici, mais vous en aurez assez pour aller plus loin si vous le souhaitez.
1. Qu’est-ce qu’un parser
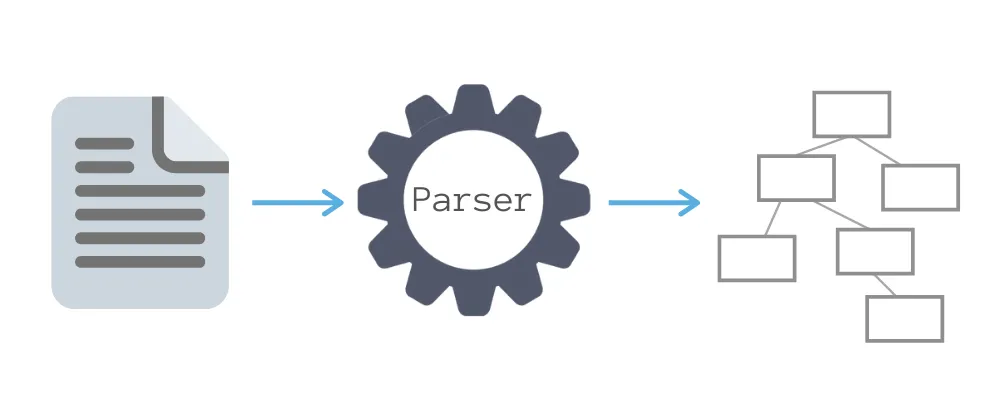
Un parser est un programme qui génère une structure de données intermédiaire à partir d’une chaîne de caractères en entrée. Le parsing se déroule le plus souvent en deux phases :
-
Analyse lexicale (aussi appelée lexing ou tokenization)
L’objectif de la tokenization est de générer des tokens à partir du programme en entrée, qui n’est à ce stade qu’une simple chaîne de caractères brute (n’importe quel fichier source, en réalité :
.js,.rs,.go,.py, etc.). Les tokens sont des ensembles de caractères qui décrivent des morceaux de code. -
Analyse syntaxique
Après la tokenization, l’analyse syntaxique prend les tokens produits et génère une structure de données intermédiaire décrivant ces tokens et leurs relations. Spoiler : cette structure est le plus souvent un arbre syntaxique abstrait (AST).
Voici un schéma d’un processus de parsing classique :

2. Qu’est-ce qu’un arbre syntaxique abstrait
Comme mentionné, un arbre syntaxique abstrait est l’une des structures de données qui peuvent être générées lors du parsing d’un code source (d’autres existent, comme les arbres syntaxiques concrets, selon le cas d’usage).
L’objectif de cette représentation intermédiaire est de disposer d’une façon standardisée de représenter le code, facile à manipuler, sans aucune perte d’information.
Le mot-clé est standardisée. Parce que l’AST est une structure intermédiaire, l’objectif global est de pouvoir transformer l’arbre en tout ce que l’on veut, par exemple pour produire un programme dans un langage entièrement nouveau, comme générer du JavaScript à partir de Scala, ou, plus couramment, du JavaScript à partir de TypeScript.
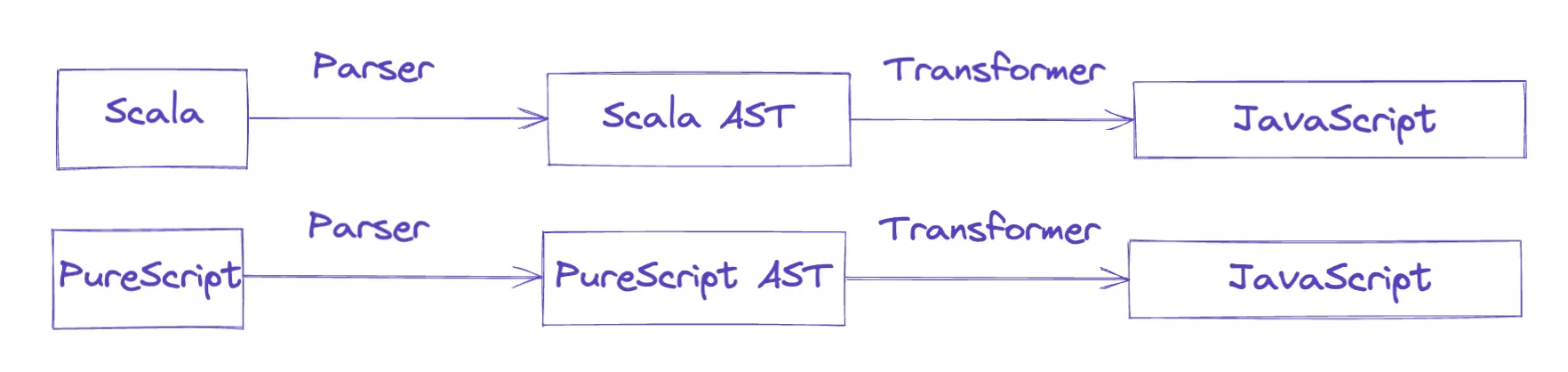
Pour rendre cela possible, chaque écosystème/langage dispose de spécifications strictes décrivant la forme standard de son propre AST. Pour JavaScript, il s’agit de la spec ESTree. Ce format standardisé permet à n’importe quel parser (écrit dans n’importe quel langage) de produire un AST commun, qui peut ensuite être interprété par n’importe quel interpréteur (lui aussi écrit dans n’importe quel langage).
3. Comment utiliser un arbre syntaxique abstrait
Pour les compilateurs, un AST est une structure de données intermédiaire qui peut être transformée pour produire du byte code ou une autre cible source : par exemple TypeScript émet du JavaScript en utilisant son propre AST.
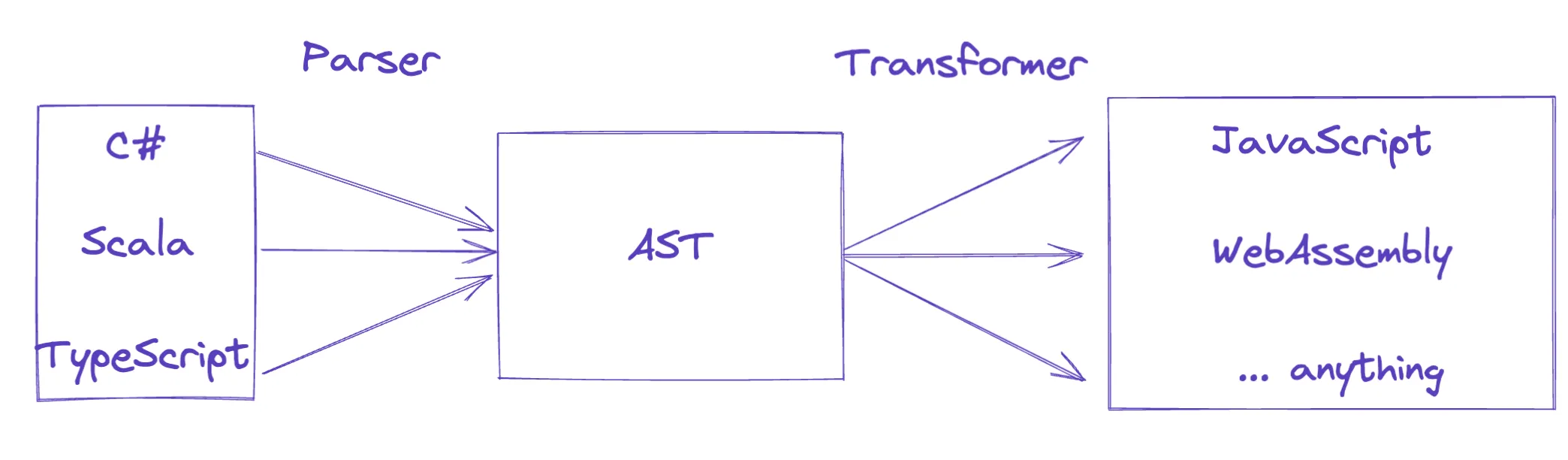
Dans le contexte de l’analyse statique, en revanche, l’AST est le plus souvent notre structure de données finale, car il nous permet d’inspecter directement les patterns du code source (sans transformation supplémentaire).
En nous appuyant sur la spec qui décrit la forme de l’AST, nous, en tant que développeurs d’analyse statique, pouvons déterminer n’importe quelle règle ou condition statique. Il s’agit seulement de trouver les bonnes combinaisons de structures de données.
Pour explorer les structures d’AST de différents langages, je recommande vivement AST Explorer.
Concluons par un exemple
Pour démontrer un petit outil d’analyse statique en action, voici un cas d’usage tiré de skott, une bibliothèque qui construit un graphe orienté des relations entre les fichiers d’un projet Node.js.
Si vous n’êtes pas tout à fait sûr de l’utilité des graphes orientés, voyez la série que j’ai écrite sur le sujet.
Pour construire ce graphe orienté, skott doit :
- prendre le point d’entrée du projet et le parser,
- trouver statiquement les instructions import/export à partir de l’AST,
- suivre récursivement les fichiers importés/exportés jusqu’à ce que tous les fichiers aient été découverts.
Allons-y.
1. Parser le point d’entrée
index.js
import { runMain } from "./program.js";
import { makeDependencies } from "./dependencies.js";
// faire quelque chose avec runMain et makeDependenciesUne fois que nous avons lu le point d’entrée, nous pouvons utiliser skott pour extraire les instructions import. Voici un extrait simplifié du code de skott :
async function walk(fileContent: string): Promise<ModuleWalkerResult> {
const moduleDeclarations = new Set<string>();
const { parseScript } = await import("meriyah");
const node = parseScript(fileContent, {
module: true,
next: true
});
const isRootNode = node.type === "Program";
walkAST(isRootNode ? node.body : node, {
enter(node) {
if (isEcmaScriptModuleDeclaration(node)) {
moduleDeclarations.add(node.source.value);
}
}
});
return { moduleDeclarations };
}Nous importons parseScript depuis meriyah, un parser JavaScript (cela aurait pu être babel, acorn ou swc : peu importe, du moment qu’ils implémentent correctement la spec). Parser le contenu du fichier renvoie le nœud racine de l’arbre syntaxique abstrait. À partir de là, il ne reste plus qu’à parcourir récursivement l’arbre entier et à trouver les instructions import.
Pour garder l’exemple simple, nous ne suivons ici que les modules ECMAScript, mais skott gère aussi les modules CommonJS.
Comment trouver une instruction import à l’intérieur de l’AST ?
Regardons la spec ESTree pour es2015 pour voir comment une instruction import est représentée :
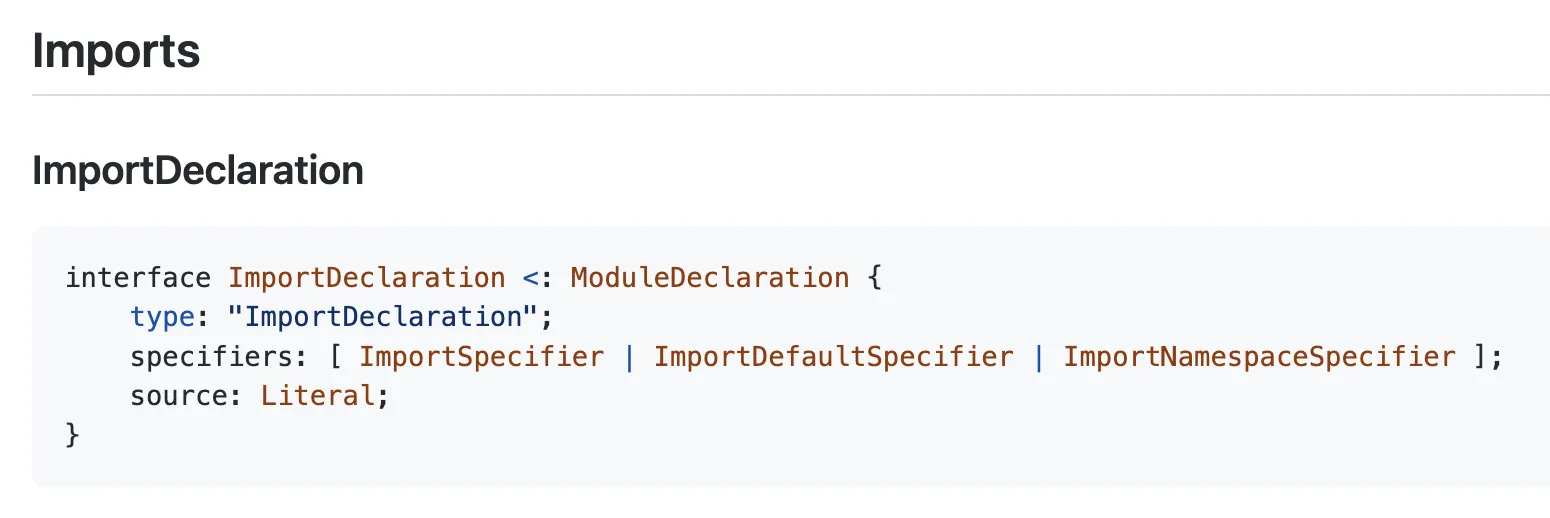
Plutôt simple : chaque fois que nous rencontrons un nœud dont le type === "ImportDeclaration", nous savons qu’il s’agit d’une instruction import. Voici donc la fonction qui détecte une instruction import es2015 :
function isEcmaScriptModuleImport(estreeNode: TreeNode): boolean {
return estreeNode.type === "ImportDeclaration";
}Parfait : nous sommes maintenant capables de trouver toutes les instructions import de n’importe quel fichier JavaScript. À l’aide de l’AST, nous pourrions aussi récupérer l’emplacement de l’import dans le fichier et, par exemple, le mettre en surbrillance dans VS Code.
Grâce à notre analyse statique, nous pouvons à présent générer et afficher le graphe à partir de tous les imports collectés :
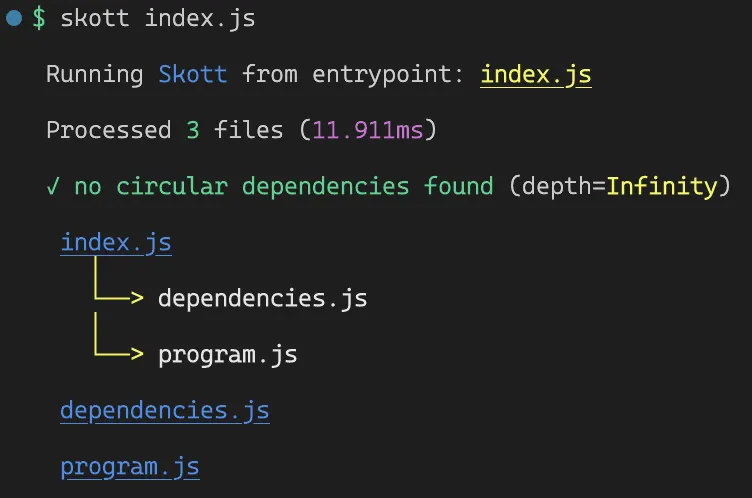
Trois nœuds ont été trouvés (les trois seuls fichiers du projet d’exemple), et des dépendances ont été établies entre index.js et ses deux enfants importés.
Conclusion
Si vous êtes arrivé jusqu’ici, vous avez probablement saisi les fondations des parsers et des arbres syntaxiques abstraits, et c’est exactement le but.
Le prochain chapitre de la série couvre le Test-Driven Development et l’injection de dépendances, les disciplines qui ont rendu tout le pipeline d’exploration/parsing/analyse de skott entièrement testable.
skott est open source : stars, issues et retours sont les bienvenus sur GitHub.